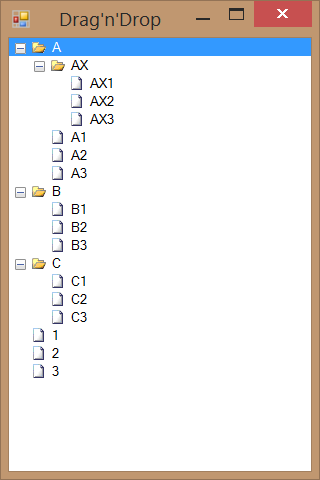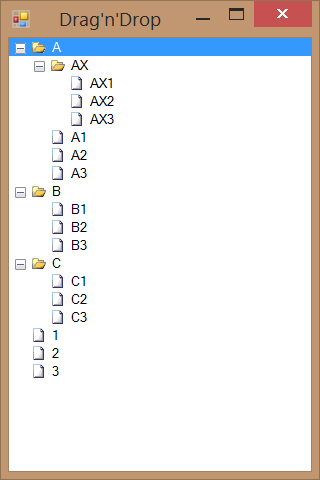
If you have a TreeView, chances are that you want it sorted and with a drag&drop functionality. And that is not too hard.
In order to sort items, don’t forget to assign TreeViewNodeSorter property. This requires simple IComparer, e.g.:
internal class NodeSorter : IComparer {
public int Compare(object item1, object item2) {
var node1 = item1 as TreeNode;
var node2 = item2 as TreeNode;
if (node1.ImageIndex == node2.ImageIndex) {
return string.Compare(node1.Text, node2.Text, StringComparison.CurrentCultureIgnoreCase);
} else {
return (node1.ImageIndex == 0) ? -1 : +1;
}
}
}
This will ensure that “folders” (with ImageIndex==0) are sorted before files (any other value of ImageIndex). All that is left is to call Sort method when needed.
In order to support drag&drop, a bit more work is needed. Before we even start doing anything, we need to set AllowDrop=true on our TreeView. Only then we can setup events. To initiate drag we just work with ItemDrag event:
this.DoDragDrop(e.Item, DragDropEffects.Move);
In DragOver we need to check for “droppability” of each item. Rules are simple; We allow only tree nodes in; if we drop file on file, it will actually drop it in file’s folder; and don’t allow parent to be dropped into its child. This class will then either allow movement (DragDropEffects.Move) or it will deny it (DragDropEffects.None).
var fromNode = e.Data.GetData("System.Windows.Forms.TreeNode") as TreeNode;
if (fromNode == null) { return; }
var dropNode = tree.GetNodeAt(tree.PointToClient(new Point(e.X, e.Y)));
while ((dropNode != null) && (dropNode.ImageIndex != 0)) {
dropNode = dropNode.Parent;
}
var noCommonParent = (fromNode.Parent != dropNode);
while (noCommonParent && (dropNode != null)) {
if (fromNode == dropNode) { noCommonParent = false; }
dropNode = dropNode.Parent;
}
e.Effect = noCommonParent ? DragDropEffects.Move : DragDropEffects.None;
Final movement happens in DragDrop event. First part is same node discovery process we had in DragOver. After that we simply move nodes from one parent to another and we wrap all up by performing a sort.
var fromNode = e.Data.GetData("System.Windows.Forms.TreeNode") as TreeNode;
var dropNode = tree.GetNodeAt(tree.PointToClient(new Point(e.X, e.Y)));
while ((dropNode != null) && (dropNode.ImageIndex != 0)) {
dropNode = dropNode.Parent;
}
var fromParentNodes = (fromNode.Parent != null) ? fromNode.Parent.Nodes : tree.Nodes;
fromParentNodes.Remove(fromNode);
if (dropNode == null) {
tree.Nodes.Add(fromNode);
} else {
dropNode.Nodes.Add(fromNode);
}
tree.Sort();
tree.SelectedNode = fromNode;
Full sample can be downloaded here.
PS: In sample code you will see that I use ImageIndex==0 to determine whether node is of folder type. In real program you would probably go with sub-classing TreeNode.