Brother MFC in Isolated Guest Network
I have already written how to poke holes in guest network for Chromecast and that method is sufficient for vast majority of devices. However, occasionally you might stumble upon device presenting a bit more challenge. One example is my Brother MFC-J475DW or better said pretty much anything in Brother’s MFC printer lineup.
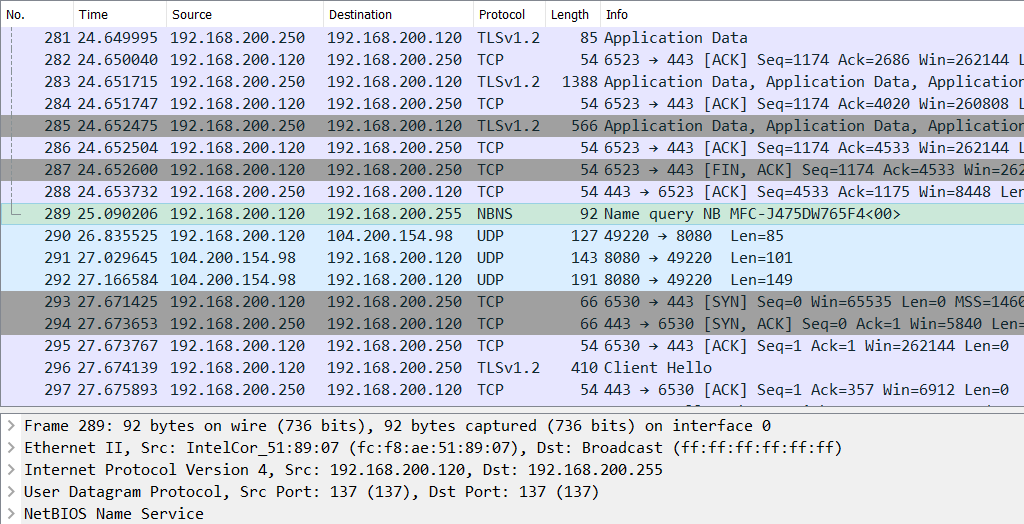
In order to determine why my printer wouldn’t work despite explicitly allowing for its MAC address, I snooped all traffic using Wireshark. As I knew printer was using IPv4 address, that was my Wireshark filter (ip.version == 4).
After playing with printer for a while (trying printing, scanning, rebooting, etc.), I stopped snoop and started going over captured packets. One packet stood out from the bunch - it was a name query packet for something looking suspiciously like my printer’s name. That packet was broadcasted to my whole network from my computer. As that packet went unanswered, my PC though there is no printer.
Armed with that knowledge, firewall-start script can be adjusted not only to allow traffic from and to the MAC address belonging to the printer (as done for the Chromecast adventure) but also to allow broadcast traffic on the first 2.4 GHz guest WiFi interface:
echo "#!/bin/sh" > /jffs/scripts/firewall-start
echo "ebtables -I FORWARD -p ARP -i ! eth0 -o wl0.1 -j ACCEPT" >> /jffs/scripts/firewall-start
echo "ebtables -I FORWARD -s ^^34:68:95:A7:64:F5^^ ``-i wl0.1`` -o ! eth0 -j ACCEPT" >> /jffs/scripts/firewall-start
echo "ebtables -I FORWARD -d ^^34:68:95:A7:64:F5^^ -i ! eth0 ``-o wl0.1`` -j ACCEPT" >> /jffs/scripts/firewall-start
echo "ebtables -I FORWARD -d ^^ff:ff:ff:ff:ff:ff^^ -i ! eth0 ``-o wl0.1`` -j ACCEPT" >> /jffs/scripts/firewall-start
echo "logger Poked hole for Brother MFC printer" >> /jffs/scripts/firewall-start
chmod a+x /jffs/scripts/firewall-start
rebootPS: During snooping do close all other programs that are using network and try to keep any non-printer activity to a minimum. Makes snoop analysis much easier.