Installing Windows 8.1 (Or 8) Without a Product Key
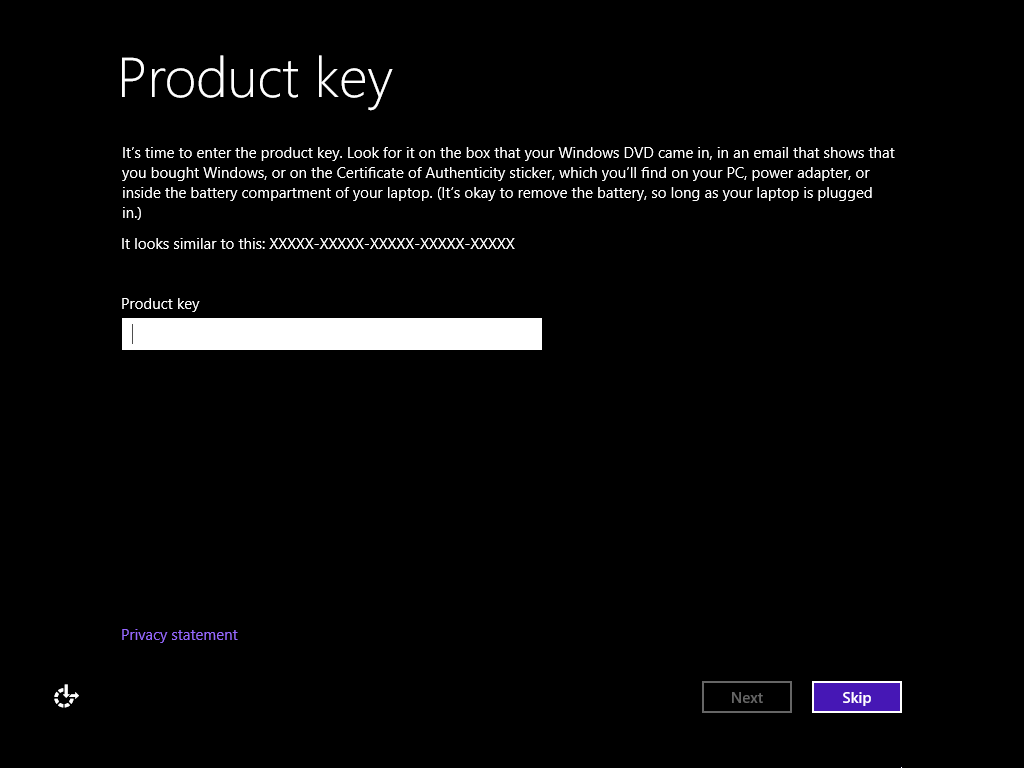
One great feature Windows 7 was possibility to install them without needing a key. Instead of entering 25-digit key, you could just select skip and Windows would give you 30 days after install to setup everything before requiring valid product key.
I found this really useful during setup of a new machine when I would have multiple reinstalls while trying out various drivers and performing their troubleshooting. Only once I was perfectly satisfied with machine, I would activate it.
More than once I also used this feature to reproduce a bug in different OS language (e.g. German). Mind you, I did have keys for that particular version (MSDN subscription is a great thing) but I was regularly too lazy to look key up for a version that would essentially get installed and deleted within a day.
Thus I was really pissed off when I found that feature was missing in Windows 8. But I was wrong. Feature is still present in setup. Only now it requires some preparation first.
Very first step is to copy all files from Windows DVD. Assuming that you have your DVD at letter W: and that you want staging directory at C:\Windows81, this would be:
ROBOCOPY W:\ C:\Windows81 /MIR
…Once copy operation has completed, we need to create ei.cfg in C:\Windows81\sources directory. In my case I wanted to specify Professional edition expecting retail key so I created file with following content:
[EditionID]
Professional
[Channel]
Retail
[VL]
0Only thing missing is creating new ISO file that we can burn on DVD. While this is not strictly necessary if you are creating bootable USB, I find having pre-prepared image an useful step. If nothing else, it is easier to backup a single ISO file than over a writable USB.
For bootable image creation we need Windows Assessment and Deployment Kit (or Windows ADK) for desired Windows version. Since I wanted to adjust Windows 8.1, I downloaded Windows ADK for Windows 8.1 but Windows 8 ADK is also freely available. Only thing that you really need to install for this guide are Deployment Tools. All other stuff you can uncheck.
To create bootable ISO image, I enter cmd.exe and there execute:
CD "C:\Program Files (x86)\Windows Kits\8.1\Assessment and Deployment Kit\Deployment Tools\x86\Oscdimg"
OSCDIMG.EXE -u1 -bC:\Windows81\boot\etfsboot.com C:\Windows81 D:\Windows81.iso
OSCDIMG 2.56 CD-ROM and DVD-ROM Premastering Utility
Copyright (C) Microsoft, 1993-2012. All rights reserved.
Licensed only for producing Microsoft authorized content.
Scanning source tree (2000 files in 803 directories)
Scanning source tree complete (2094 files in 867 directories)
Computing directory information complete
Image file is 3984359424 bytes
Writing 2094 files in 867 directories to D:\Windows81.iso
100% complete
Final image file is 3990419456 bytes
Done.This will create bootable Windows81.iso image in a root directory of your second drive. If you have a single drive, place file into a subdirectory. Otherwise file will be written in Virtual store (usually at %USERPROFILE%\AppData\Local\VirtualStore).
Finally we have image that will not ask you for key during install and it will allow you to skip key entry for 30 days. Just burn it to CD or make bootable USB and you are ready to go.
PS: This also means that you can use your Windows 8 key to activate Windows 8.1 after installation is done. While Windows 8 key won’t work during installation, it will work nicely once everything is fully installed.
PPS: If you omit EditionID from ei.cfg, you will get an option to select edition that you would like (Professional or Core).
PPPS: No, this is not a hack. Microsoft has it all documented (both ei.cfg and oscdimg.exe).
[2013-10-20: You can download ISO directly from Microsoft (see instructions at SuperSite).]